
Deploying Robots in the Real World
The systems infrastructure gap between impressive VLA demos and actual robot deployment
The bitter lesson seems to really be hitting the sweet tooth of ML researchers turned roboticists. Classical roboticists' methods relying on control theory, perception, and intricate co-design of mechanical and software subsystems are seemingly outpaced by the version of robotics simply being a factor of scale. The story follows as foundation models got big enough, someone plugged a vision-language model into a robot arm, trained it on ten thousand hours of teleoperation data, and now robots can fold laundry in houses they've never seen. Optimists in scaling robot models have high conviction that the hard part is done and it's simply just more data and bigger clusters that are needed to achieve general robotic intelligence.
This story is not wrong.. rather it's just wildly incomplete.
Physical Intelligence's π₀.5 really can clean up a stranger's kitchen. Their π₀.6, trained with RECAP (an offline RL recipe using advantage conditioned policies), can make me a much needed espresso on a professional machine it's never touched. The nice thing is these aren't just demo tricks that are handpicked, they genuinely represent open-world generalization that would have seemed absurd three years ago.
But here's the question that doesn't get asked at the conference poster sessions. How does that model actually run?
Not during the demo, but during deployment. In a warehouse in Osaka, on a mobile manipulator with a 40-watt power budget, all at 50Hz, for eight hours with no cloud connection because the facility manager doesn't want their robot's sensor feed crossing a network boundary, while the model is 7 billion parameters in FP16 and generates 400 image tokens per control step.
If you've spent time thinking about inference systems, the kind of thinking that went into vLLM, FlashAttention, or PagedAttention, you'll recognize the problem immediately. The rest of this post is for everyone else.
The stack that came before
To understand what's missing it helps to understand what we had, and the classical robotics stack that dominated from the mid-1990s through the early 2020s and still runs most deployed industrial systems today was built around one principle above all others: make everything observable. The pipeline was explicitly modular, running perception into state estimation into planning into control, and at every stage you got something you could inspect — object poses with uncertainty estimates, occupancy grids, trajectory splines you could replay and validate. When something went wrong, and it always went wrong, you could step through each node and find the one that broke.
Perception → State Estimation → Planning → ControlROS and its successor ROS2 encoded this philosophy into the middleware itself, where nodes are processes, topics are typed message streams, and the entire design assumption is that robots break in confusing ways and your only hope is to make the internal state legible. You could attach a debugger to any node, log every message, replay a failure mode from a bag file, and get a clean answer about what happened and where.
This philosophy came with a very real tax though. The modular stack was brittle at exactly the seams where it connected modules together, and perception errors cascaded into planning failures in ways that were genuinely hard to anticipate ahead of time. Precise geometric manipulation in controlled environments was well within reach, but anything requiring contextual understanding of an unstructured environment was essentially impossible — you couldn't tell a ROS-era robot to "clean up the kitchen" because that requires semantic reasoning that no amount of carefully designed state estimation nodes was ever going to provide. The modular stack was debuggable but not generalizable, and that was the tradeoff it made, consciously or not.
How the end-to-end revolution changed the terms
The transformer's core insight, that you can model arbitrarily complex conditional distributions over sequences if you scale the architecture and the data, turned out to apply to robot control with surprisingly minor modifications. The key move was collapsing the entire pipeline into a single learned conditional policy:
$$\pi_\theta(a_t \mid o_t, l)$$where \(o_t\) is a stack of camera observations (typically 400+ tokens from a ViT encoder), \(l\) is a language instruction, and \(a_t\) is the action vector you actually execute. All the geometric reasoning, affordance detection, semantic grounding, and motion planning that used to live in separate debuggable modules now lives implicitly in the hidden states of a transformer that you trained end-to-end on demonstrations. You don't know what's in there, and increasingly the point is that you don't need to.
The generalization gains from this were real and large. Chi et al.'s 2023 Diffusion Policy paper showed roughly 47% average improvement in task success over prior imitation learning baselines, which wasn't a marginal gain but a structural one driven by a fundamentally different modeling assumption. On contact-rich tasks like ToolHang, prior methods that optimized L2 regression loss would output the conditional mean of a multimodal action distribution, which in practice means averaging between "go left around the obstacle" and "go right around the obstacle" and landing on "go through the obstacle." Diffusion, modeling the full conditional density \(p(a_t \mid o_t)\) via iterative denoising rather than collapsing to the mean, doesn't do this, and the difference in success rates was stark.
RT-2 (Google DeepMind, 2023) took the VLM pretraining route — start from a large vision-language model pretrained on internet-scale data, fine-tune it to output robot actions as discrete tokens, and you get zero-shot generalization to novel instructions and objects that the model had only encountered during language pretraining and never during robot training. A robot that had never been trained to pick up a Coke can could do it because somewhere in its pretrained weights it had read about Coke cans and understood what they are and roughly what picking one up should look like.
Physical Intelligence's π₀ (2024) went further still, with a 3B parameter VLA pretrained on data from 7 distinct robot configurations and 68 tasks, using a flow-matching action head that generates high-frequency action chunks. The key architectural move was separating the "thinking" — the VLM backbone, running at ~1-3Hz doing semantic interpretation — from the "doing" — the flow-matching action head, generating 50Hz motor control through 10-20 denoising steps over a chunk horizon H. This dual-system design is not an accident; it's an honest acknowledgment that the bandwidth constraints of the problem look fundamentally different at the semantic and motor levels, and trying to run one model at both frequencies simultaneously creates a constraint you can't resolve cheaply.
π₀.5 added co-training on heterogeneous data, combining robot demonstrations with high-level semantic prediction tasks, web data, and cross-embodiment transfer to get meaningful generalization to entirely new homes the model had never seen in training. π₀.6 then closed the RL loop, with RECAP training a value function alongside the VLA, conditioning policy actions on advantage estimates, and fine-tuning on autonomously collected on-robot data so the model actually gets better with experience rather than staying frozen at the performance level of the demonstration dataset.
All of this is genuinely impressive, and represents real progress. It is also, from a systems perspective, a nightmare.

The compute budget nobody talks about
Let's be concrete about the numbers, because the handwavy version of "it's hard to run on the edge" obscures what's actually going on mechanically.
A 7B parameter VLA in FP16 requires 14 GB of weights, and at batch size one — which is what you have when you're running a single robot, not a datacenter serving thousands of concurrent requests — inference is memory bandwidth bound rather than compute bound. The GPU isn't saturated by arithmetic; it's waiting on DRAM to deliver weight matrices fast enough to keep the tensor cores busy. On an H100 with ~3.35 TB/s effective memory bandwidth, a single forward pass through 14 GB of weights takes roughly 4-5ms at batch size one, which sounds fast. On an NVIDIA Jetson AGX Orin with effective bandwidth closer to 200-270 GB/s, that same forward pass takes 50-70ms before you've even accounted for the attention computation, which is where things start looking rough.
Add the action head and it gets worse. Flow-matching with 10 denoising steps means 10 forward passes through the policy network for each generated action chunk, so if each pass costs 50ms on an Orin, a single chunk generation takes 500ms total. With a chunk horizon of H=20 actions, that's 25ms amortized per executed action, putting you at roughly 40Hz for the executed control — borderline for manipulation and too slow for anything dynamic.
That's just the weight loading. Then there's the KV cache. ViT encoders at typical resolutions produce 256-400 tokens per camera frame, and with multiple cameras (which every real manipulation setup requires), a single observation can contribute 800-1200 tokens to the context window. The KV cache memory for a single transformer layer is:
$$\text{KV bytes} = 2 \cdot B \cdot T \cdot h_{kv} \cdot d \cdot \text{bytes per element}$$For a 7B model with \(h_{kv}=8\) GQA heads, head dimension \(d=128\), context length \(T=1200\), batch size \(B=1\), in FP16, that's:
$$= 2 \cdot 1 \cdot 1200 \cdot 8 \cdot 128 \cdot 2 \approx 4.9 \text{ MB per layer}$$Over 32 layers that comes out to about 157 MB just for the KV cache, which sounds manageable until you remember that the Orin has 64 GB unified memory shared between the GPU, CPU, the OS, the sensor fusion pipeline, the safety monitor, and any other models you're running. The part that really doesn't show up in benchmark papers is that this cache isn't static — if your VLA maintains a rolling observation window for temporal reasoning, which π₀.5's subtask prediction implicitly requires, the cache grows linearly with execution time. Nobody in the robotics community is calling this a memory leak yet, but that's functionally what it is.
The Jetson AGX Thor (released August 2025, now generally available) changes the arithmetic somewhat — 2,070 FP4 TFLOPS, 128 GB memory, 7.5x the AI compute of Orin, 3.5x better energy efficiency within a 40-130W configurable power envelope. A single forward pass through a 7B model at FP8 takes roughly 6-8ms on Thor, flow-matching at 10 steps drops to ~70ms per chunk, and with H=20 you're at 3.5ms amortized per executed action, now comfortably above 50Hz for reasonable manipulation tasks.
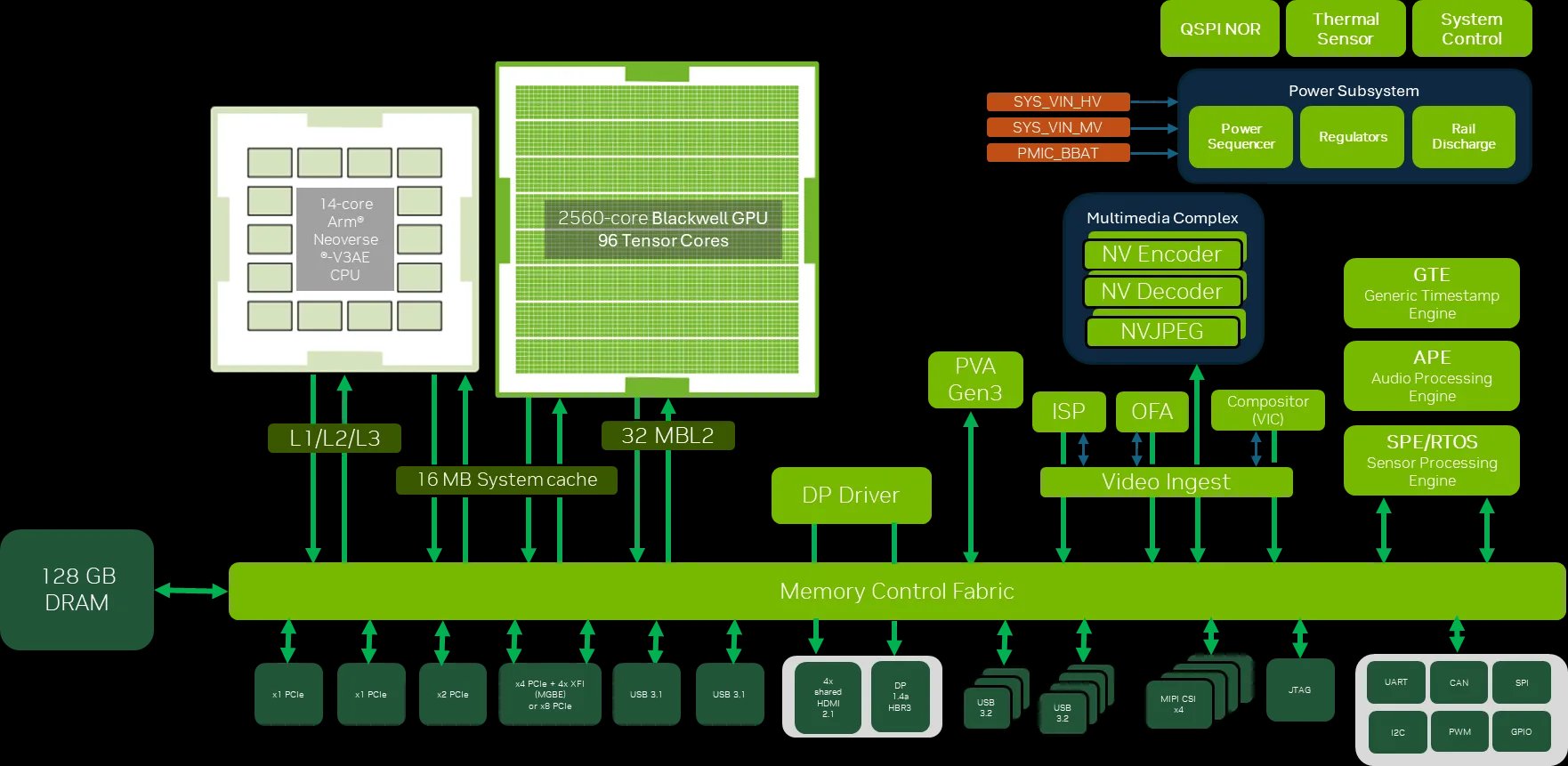
But Thor costs $3,499 for the developer kit, it's brand new, and the installed base is Orin for the foreseeable future. And even Thor's 128 GB unified memory isn't free — it's shared across the sensor stack, both models in a dual-system architecture, and whatever safety infrastructure you're running alongside them. The memory pressure is real on any edge platform that isn't a rack-mounted datacenter GPU, which is the entire point of the deployment problem.
What's actually missing in the infrastructure
Here's what bothers me most about the current state of robotics ML infrastructure, which is that the fundamental insight that unlocked LLM serving at scale simply hasn't been applied to VLAs yet, even though the same class of problem exists.
vLLM was built around the observation that memory fragmentation from variable-length KV caches wasn't just inconvenient but was the actual binding constraint on throughput, and PagedAttention solved it by treating KV cache blocks like virtual memory pages and mapping non-contiguous physical blocks to logically contiguous key-value sequences. The result was a 24x improvement in serving throughput compared to naive implementations, not because the model changed or the hardware changed, but because the system finally stopped wasting the resources it already had. The people who built it understood both the hardware (A100 HBM bandwidth, CUDA memory management, PCIe topology) and the model (how attention patterns in autoregressive generation translate to KV cache access patterns) well enough to see the mismatch and fix it.
For VLAs, nobody has done this, and the reasons aren't hard to identify once you look at how VLA inference actually differs from LLM inference.
VLAs don't generate autoregressively in the same way. The action head — whether it's flow-matching or diffusion — iterates over the same latent repeatedly rather than sequentially extending a context, so the KV cache pattern is fundamentally different. It's not a growing prefix being appended to; it's a fixed observation window being re-attended over across 10-20 denoising steps. The caching opportunity is not in the action generation itself but in the expensive visual encoding step — those 400 image tokens from the ViT that don't change at all across denoising steps for the same observation. Most VLA inference pipelines re-encode them anyway, every single denoising step.
The control loop changes the kernel design problem entirely. In LLM serving you optimize for tokens per second across many concurrent requests, but in robot serving you have exactly one request — the robot — it's real-time, and the metric is latency not throughput. To understand why this changes the kernel design problem specifically, it's worth looking at what Hazy Research has been building.
ThunderKittens makes a deceptively simple claim, which is that a modern GPU is not a matrix multiply machine but rather a manycore processor where each core efficiently runs 16×16 matrix multiplies, and everything else — the illusion of monolithic GEMMs, the abstraction of contiguous memory operations — is constructed on top of that fundamental unit. ThunderKittens builds from that substrate with tiles of data as the fundamental unit, explicit producer-consumer warp specialization for overlapping memory movement with computation, and asynchronous TMA loads that hide HBM latency behind tensor core work. On Hopper H100s a FlashAttention-3 kernel written in ThunderKittens achieves ~86% of theoretical peak FLOP/s, not because the algorithm changed but because the warp scheduling finally maps cleanly to what the silicon actually wants.
The megakernel work extends this insight from individual kernels to entire model forward passes. Hazy's diagnosis was that popular inference engines like vLLM and SGLang, running Llama-1B at batch size one on an H100, use at most 50% of available GPU bandwidth — and the culprit isn't the math but the kernel boundaries, where every transition between kernels (RMS norm, QKV projection, attention, output projection, MLP) incurs a setup and teardown period where no useful work happens and SMs sit idle while the driver launches the next kernel. At batch size one, which is exactly what a robot is, the individual operations are so memory-bound and so short that these boundary overheads dominate the total cost. The megakernel solution is an on-GPU interpreter that compiles the entire forward pass into a single persistent kernel with a virtual instruction set, allowing compute-bound operations and memory-bound operations to overlap within the same kernel and keep both tensor cores and HBM bandwidth saturated simultaneously. ThunderMLA is 20-35% faster than DeepSeek's FlashMLA, and the Llama-70B throughput megakernel beats SGLang by 22% end-to-end.
Does any of this transfer to VLA inference on edge hardware? Yes, but with a critical wrinkle that makes the VLA case harder than the LLM case.
The FlashAttention tiling argument — keep attention weights in SRAM, stream K and V from HBM in tiles, use the online softmax trick to avoid materializing the full \(n \times n\) attention matrix — makes sense when you have long sequences and large batch sizes where the compute-IO balance works out and collapsing the \(O(n^2)\) memory footprint to \(O(n)\) is a huge win. For VLA decode-style inference, where you have one new query token attending over a large cached key-value context, the arithmetic flips. Your query is a single vector, your keys and values are \(T \times d\) matrices sitting in HBM where \(T\) might be 1200, and the operation is a streaming reduction where you load a tile of K, compute dot products, accumulate softmax stats, load the corresponding V tile, take a weighted sum, and repeat until you've covered all \(T\) positions. There's no large query matrix to tile across, the reuse opportunity that makes FlashAttention shine doesn't exist in the same form, and the operation is almost purely bandwidth-bound — you're moving \(2 \cdot T \cdot h_{kv} \cdot d\) bytes per decode step with proportionally tiny compute.
This is exactly the regime where megakernel-style thinking is most valuable, and where Jetson Thor's Blackwell architecture with its new generation TMA that can asynchronously issue HBM loads directly from device-side code without stalling the SM becomes genuinely useful — you can architect a VLA decode kernel where one group of warps is streaming the next KV tile from HBM while another group is running the softmax reduction on the tile already in SRAM, applying exactly the producer-consumer warp specialization that ThunderKittens makes tractable.
Here's the wrinkle though. The VLA runs the same decode step 10-20 times per control step, because that's how flow-matching works — each denoising step processes the same observation tokens with a different noisy action latent, so the KV cache for those 1200 visual tokens is identical across all denoising steps for a given observation. In standard inference frameworks this means you're reloading roughly 157 MB of KV cache from HBM 10-20 times every single control cycle, which is deeply wasteful. A megakernel that understood the denoising loop structure could hoist the visual KV computation entirely outside the denoising loop, compute it once, and keep it resident in SRAM across all denoising steps — the opportunity is real and the bandwidth savings would be substantial, but nobody has written this kernel yet because the robotics community doesn't spend much time at the PTX level and the kernel community doesn't spend much time thinking about denoising loops.
The same gap shows up at the ViT-to-transformer boundary, where in current VLA implementations the ViT produces a 400-token embedding tensor, writes it to HBM, and the transformer backbone reads it back on every inference step — a roundtrip that costs ~3-5ms on an Orin at 200 GB/s effective bandwidth, easily eliminable by fusing the ViT output directly into the first transformer layer's QKV projection and never touching HBM in between. This is the same cross-kernel-boundary fusion megakernels do for LLM layers, but requires ThunderKittens-style tile-based programming with explicit memory hierarchy management rather than vanilla CUDA or Triton.
Beyond the kernel story, two other things are completely missing. First, there's no equivalent of TensorRT for the VLA pipeline as a whole — NVIDIA's TensorRT can compile a VLA model for Jetson, but it doesn't know about the temporal structure of a control loop, the chunk boundary problem, the dual-system synchronization problem, or the KV reuse opportunity across control steps. It optimizes the model. It doesn't optimize the inference system. Second, the observability tooling is essentially nonexistent — when your LLM hallucinates you can trace the attention pattern, inspect the residual stream, run a sparse autoencoder decomposition, and identify which features were causally active, but when your VLA drops a mug you have the action chunk that got executed and a video, and that's it. Langfuse doesn't work here, Foxglove logs topics but knows nothing about internal model state, and W&B tracks training metrics but nothing about deployment behavior. The gap between "model trained successfully" and "model behaving correctly in production" is completely dark, and that's why robot deployment cycles are measured in months of on-robot debugging rather than days of software iteration.
The structured prior camp is solving a different part of the same problem
It would be a mistake to read all of the above as "just scale the VLA and build a better serving stack," because there's a separate research tradition that has been quietly making the deployment problem tractable from a fundamentally different angle, and it's worth understanding what they're actually doing and why.
Yunzhu Li's RoboPIL lab at Columbia is working on what they call structured world models, which insist on learning physics-inspired, interpretable predictive representations rather than opaque latent dynamics. This sounds like it might be a step backward from the "just train on everything" paradigm, but the practical argument for it is strong — representations that are grounded in interpretable structure tend to be more data-efficient to learn and cheaper to run at inference time, which matters enormously in the deployment regimes where the PI paradigm breaks down.
D3Fields (CoRL 2024) is a good example of this — it builds a scene representation that combines 3D Gaussian features from multiple views with semantic descriptors from 2D foundation models, producing a dynamic 3D field over the workspace with the key property that because the descriptor space is grounded in pretrained visual features, a policy trained on one set of objects zero-shot generalizes to novel instances with similar semantic properties. The representation is not opaque the way a transformer's hidden states are opaque; you can inspect which descriptors are tracking which objects, verify that the semantics are sensible, and diagnose failures geometrically rather than by staring at activation tensors.
ReKep (Wenlong Huang, Yunzhu Li et al., RSS 2024) takes an even more striking approach by using a VLM to generate relational keypoint constraints — Python functions mapping 3D keypoint positions to numerical costs — that encode the task semantics, and then solving those constraints with an off-the-shelf optimizer rather than running a monolithic policy. The VLM runs once to generate the constraint structure; the control loop runs fast because it's solving a constrained optimization problem, not running a 7B parameter model through 10 denoising steps at 50Hz. KUDA (2025) takes the same sparse keypoint representation and makes it do double duty as both a compressed state for a learned dynamics model and a visual prompt for a VLM to interpret task specifications, getting two expensive things for roughly the price of one.
The pattern across all of RoboPIL's work is finding the representation that makes the problem tractable, where tractable means both learnable from limited data and executable within real compute budgets. This is a fundamentally different bet from Physical Intelligence's approach of collecting enough data and scaling the model until the representation learns itself, and both bets are valid — they're just optimizing for different deployment regimes. The PI paradigm wins when you have abundant data, a large pre-training cluster, and reasonable edge hardware. The structured prior paradigm wins when you're data-limited, compute-constrained, or need interpretability, which describes the majority of real industrial deployment scenarios that aren't funded at $400M and running in carefully controlled conditions.
The interesting open question is whether these approaches eventually converge — does π₀.5's co-training on high-level semantic prediction implicitly learn something like keypoint-structured representations in its hidden states? Does KUDA's sparse dynamics model benefit from VLA pre-training the way fine-tuned models benefit from large pretrained backbones? These are genuinely open questions, and answering them requires the probing infrastructure, activation analysis tools, and mechanistic interpretability methods that don't currently exist for either class of model in deployment.
Simulation is a crutch we keep leaning on wrong
Before you can deploy a VLA anywhere you have to train it on something, and Physical Intelligence's π₀ pretraining used 10,000+ hours of robot data from physical hardware — which is expensive enough that it's a significant reason why Physical Intelligence raised $400M, not primarily for compute but for the teleoperation hardware and human labor needed to generate that training data at the scale required.
The obvious alternative is simulation, and NVIDIA Isaac Sim can generate physically accurate synthetic data at remarkable scale, compressing what would be 18 months of real-world data collection into 72 hours of simulation through domain randomization over textures, lighting, object configurations, and physics parameters. Isaac Lab's GPU-parallelized RL can train locomotion policies that transfer zero-shot to real hardware with some impressive results. But a 2024 benchmark found that even state-of-the-art sim2real pipelines still exhibit 12-18% performance degradation when transitioning from controlled lab settings to unstructured real environments, and for contact-rich manipulation (the exact tasks where VLAs show the most promise), the degradation is worse because contact physics are chaotic in the formal sense — small perturbations compound in ways that are hard to capture even in high-fidelity simulation.
This is where world models in the Dreamer/RSSM sense become interesting not as policy substrates but as evaluators — if you have a learned dynamics model that accurately predicts how the environment will evolve under your policy's actions, you can evaluate that policy in simulation without running it on hardware, which would compress the iteration cycle enormously. Yunzhu Li's group framed this precisely as an open question worth taking seriously: how accurate must a simulator be for evaluation to be meaningful, and how do we get there? We don't have a good answer yet. The closest approach is iterating between real-world failures and simulation, using the failures to identify which aspects of the physics model are wrong and tightening domain randomization to cover those failure modes, which is painstaking work that Isaac Sim makes faster but doesn't make solved.
The deeper issue is that "accurate enough for evaluation" and "accurate enough for training" are different thresholds, and we don't have formal criteria for either. This matters enormously for deployment because the alternative to a reliable simulator is expensive on-robot debugging, which loops back to the observability problem — if you could instrument the VLA's internal state during a failure, you could identify what it thought was happening in the environment, compare that to what was actually happening, and generate targeted simulation scenarios to close that specific gap. You'd be using the model's own internal representations to tighten the simulator. Nobody is doing this yet.
The edge question, asked honestly
Before getting into what the right inference stack looks like, it's worth addressing the question that sometimes gets hand-waved: why does any of this need to run on the robot at all? Cloud GPUs are cheap, abundant, and fast — an A100 can run a 7B VLA forward pass in ~4ms, so why not offload inference to a rack somewhere and send actions over the network?
The answer is latency, but not in the vague hand-wavy sense the word usually gets deployed. The round-trip time from a robot to a cloud endpoint consists of physical transmission over WiFi or 5G (1-5ms within a facility, 20-100ms over the public internet), ingestion and queuing at the cloud endpoint (50-100ms when there's any load), inference time on whatever GPU you're allocated (4-15ms for a 7B model, but with queuing jitter), and the return path. Total on a good day: 75-200ms. With realistic jitter: 200-800ms.
A freshly published measurement study (Pohland et al., arXiv 2603.18284, March 2026) ran exactly this experiment — the first rigorous measurement of mobile robotic manipulation workloads across Jetson Orin, Jetson Thor, an edge GPU (L4), and a cloud A100. The finding is damning: offloading VLA inference to cloud-class GPUs reduces raw compute time but the network latency introduced by even local wireless links was enough to drop VLA manipulation accuracy by a measurable amount, and for the full workload stack, naive cloud offloading is described as "impractical" due to bandwidth requirements. Meanwhile the larger onboard GPUs drain robot batteries up to 160% faster than smaller ones.
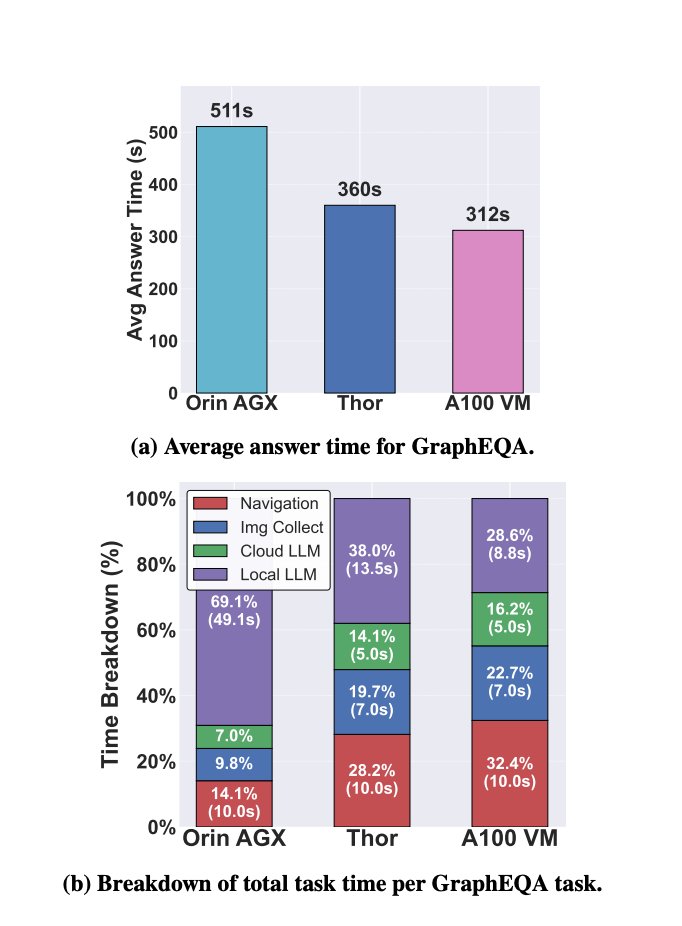
So the question isn't necessarily cloud vs. edge. The question to consider is: given that edge inference is mandatory for a large and growing class of deployments, how do you make it work with models that are designed for and trained on datacenter-grade hardware?
The part that barely appears in the robotics ML literature is the closed-loop control constraint, which is that a robot manipulating a dynamic object isn't querying an API but running a control loop, and the difference is fundamental. In an API interaction, a slow response means the user waits. In a control loop, a slow response means the plant state evolves while you're thinking and your action, when it finally arrives, was computed for a state that no longer exists. For a 50Hz controller the plant moves every 20ms, so an inference delay of \(d\) control steps means your action chunk was conditioned on observations that are \(d\) steps stale by the time the first action executes, and because VLAs generate chunks of \(H\) actions, by the time you execute the last action in the chunk the staleness is \(d + H\) steps — potentially hundreds of milliseconds of open-loop drift in a scene that has changed.
Physical Intelligence confronted this directly and honestly. In π₀, π₀-FAST, and π₀.5, they did not use a real-time inference strategy: "We executed actions synchronously, meaning that we would finish executing one chunk, wait for model inference, and then begin executing the next one." It also means the robot was frozen during inference — a 200-500ms pause every second of operation that is fine for laundry folding but is a hard ceiling on any task requiring dynamic reactivity.

Physical Intelligence's Real-Time Chunking (RTC) paper directly addresses this (Black et al., 2025). RTC treats chunk generation as an inpainting problem where rather than waiting for a full new chunk before acting, the actions are "frozen" and are guaranteed to execute before the new chunk arrives, and the model then "inpaints" the remaining actions conditioned on the frozen prefix and the current observation. This is clever and more importantly generalizes well, as RTC completed tasks like striking a match and plugging in an Ethernet cable with injected delays of over 300ms. But RTC requires understanding the chunk structure deeply, tracking which positions are frozen vs. free, and maintaining consistency guarantees across chunk boundaries — this is exactly the kind of thing a performant serving runtime should handle, and it currently lives in research codebases.
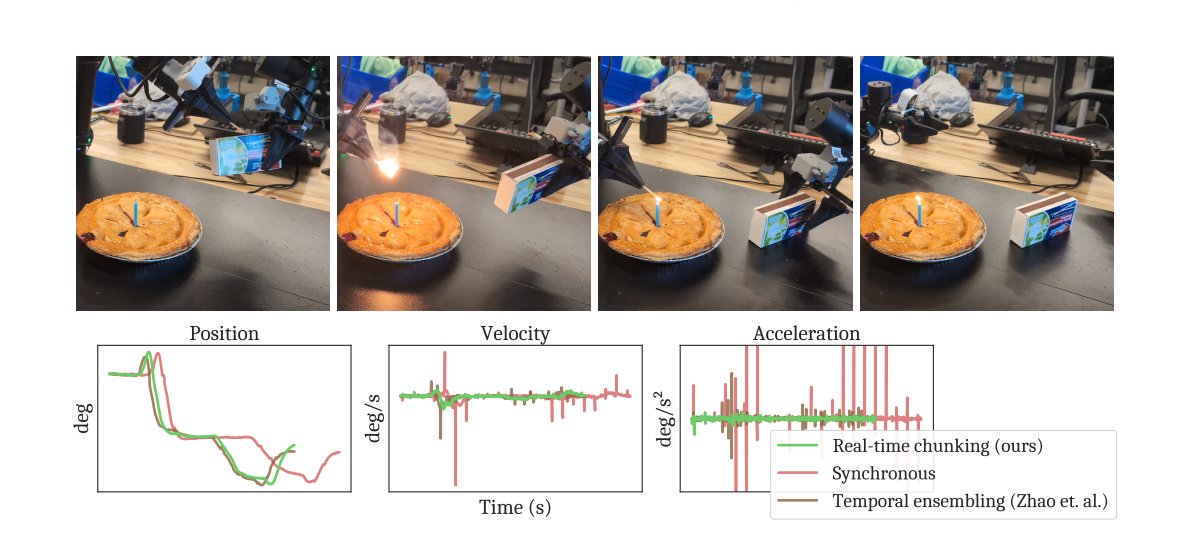
The A2C2 paper (Leave No Observation Behind, 2025) takes a different angle, attaching a lightweight correction head to the base VLA that can modify the current chunk's actions based on fresh observations without running the full policy at control frequency, with the base policy running slowly in the background. This is a dual-system architecture emerging at the algorithm level to compensate for a systems-level gap, which is itself evidence that the chunk boundary and inference latency problems are real enough that multiple independent groups are building workarounds rather than waiting for someone to build the infrastructure.
The industrial deployment argument is even starker and harder to handwave away. A factory running a high-speed conveyor line at 400 units/minute has 150ms between units, and a cloud round-trip at 500ms means you react to unit \(n\) when unit \(n+3\) is already at the inspection point — these systems fail in exactly this way in production. The regulatory dimension adds another hard constraint: European GDPR and emerging US executive orders on operational technology security mean that many manufacturing, healthcare, and defense deployments cannot legally send sensor data to cloud endpoints at all, so for surgical robots, pharmaceutical production lines, and automotive assembly facilities, edge isn't an optimization but the only legal option.
What the right stack actually looks like
Now we can be concrete about what it would mean to actually solve this, because the problem isn't any one component but the fact that every component needs to be rethought together for a problem structure that differs from LLM serving in ways that aren't immediately obvious.
The chunk boundary problem is unsolved at the systems level. Let \(\Delta t\) be the controller timestep duration (20ms at 50Hz), \(d\) be the inference delay in controller steps, \(H\) be the prediction horizon (chunk size), and \(s\) be the execution horizon (how many steps you actually execute before replanning). The observation conditioning your next chunk was captured \(d\) steps ago, and the last action in your execution horizon was conditioned on an observation \(d + s\) steps old. For π₀ with \(H = 50\) actions (1 second at 50Hz) and ~200ms inference time on an Orin (\(d \approx 10\) steps), by the time you execute action 50 your policy was conditioned on observations from 1.2 seconds ago — fine in a static scene, a source of failures in anything dynamic.
Temporal ensembling (running multiple overlapping chunks and taking an exponentially weighted average, from ACT, Zhao et al. 2023) doesn't work for multimodal distributions — the weighted average of "go left around the obstacle" and "go right around the obstacle" is "go through the obstacle." RTC is better but requires deep integration with the denoising process. What a proper serving runtime would provide is a chunk scheduler that tracks execution state, knows which positions are committed vs. free, implements RTC-style inpainting as a first-class primitive, and exposes a clean next_action() API to the low-level controller that guarantees smooth, consistent actions with bounded latency. This is the robotics equivalent of continuous batching in LLM serving — a scheduling primitive so fundamental it should be infrastructure, not per-paper research code.
KV reuse across control steps is the highest-leverage optimization nobody has implemented. At 50Hz, consecutive camera frames share over 90% of their content, yet current VLA pipelines re-encode the full observation from scratch at every inference step. The LLM analog is prefix caching in vLLM, where two requests sharing a common prefix reuse the corresponding KV blocks rather than recomputing them. The VLA analog is temporal KV caching — tracking which spatial regions of the observation have changed between timesteps, invalidating only those KV blocks, and reusing the rest. This could reduce ViT encoding cost by 60-80% in typical manipulation episodes, and combined with hoisting the visual encoding entirely outside the denoising loop (since those 800 image tokens are identical across all 10-20 denoising steps for a given observation), the total bandwidth savings are the difference between 200ms per chunk and closer to 60ms per chunk. Nobody has built this, and the gap is that it requires a serving runtime that understands both the temporal structure of a control episode and the internal structure of flow-matching denoising — two things that have never been considered together.
Multi-model memory orchestration is solved in LLM serving and completely open for robotics. The dual-system architecture is now canonical — a high-level semantic model at 1-3Hz paired with a low-level motor policy at 50Hz, used by π₀, GR00T N1.5, Helix, and essentially every serious VLA deployment effort. On Jetson Thor's 128 GB unified memory, running both simultaneously is physically possible, but the memory allocation is nontrivial: the semantic model needs its full KV cache alive for multi-step reasoning (π₀.5's subtask prediction generates intermediate language tokens before actions, requiring a persistent context), the motor model needs its KV cache alive across multiple control steps for temporal consistency, and both need access to the ViT encoder output. The right abstraction is a tiered shared memory pool — always-resident buffers for active KV caches, evictable buffers for context not accessed in \(k\) control steps, a page-mapped arena for the visual feature cache — which is structurally almost exactly PagedAttention but adapted for multi-model, hard-latency-constraint operation. Nobody has built this for robotics.
Observability needs to be a first-class primitive, not an afterthought. The classical robotics stack gave you observability for free because the intermediate representations were explicitly designed as observable state — object poses as typed messages, occupancy grids in Foxglove, planning trajectories replayable from bag files. End-to-end neural policies collapsed this into residual streams of 4096-dimensional vectors spread across 32 transformer layers that you can log but can't read.
The good news is the representations are richer than they appear if you have the right tools. Linear probing consistently shows that VLA hidden states encode geometrically and semantically meaningful information — gripper pose, object affordance, and task progress are all decodable from attention head outputs, meaning the information is present even if it's not legible without the right instrumentation. Sparse Autoencoders (SAEs) can decompose the polysemantic activations of individual neurons into interpretable dictionary features by imposing an \(L_1\) sparsity penalty, and while the Anthropic interpretability team has applied this extensively to LLMs, essentially no work has applied it to VLA activations in deployment. The three signals I'd instrument first, all byproducts of the forward pass you're already running:
Denoising trajectory curvature — for flow-matching policies, let \(z_k\) be the latent at denoising step \(k\) and \(v_k = z_{k-1} - z_k\) be the velocity. The curvature:
$$\kappa = \frac{1}{K} \sum_{k=1}^{K-1} \left\| v_{k+1} - v_k \right\|_2$$measures how straight the trajectory is through latent space. A straight trajectory signals a confident, well-defined mode of the action distribution; a curved trajectory means the model is navigating between competing attractors and the specific sample you get is sensitive to initialization noise. High \(\kappa\) correlates with task failure and should trigger a replanning step or human handoff alert — you have this signal before the bad action executes.
Attention entropy — for each attention head \(h\) at layer \(l\):
$$H_{h,l} = -\sum_i \alpha_{h,l,i} \log \alpha_{h,l,i}$$High entropy means the head is diffuse rather than focused, and sudden entropy spikes in the visual cross-attention heads typically mean the robot has moved into a part of its workspace it hasn't seen in training — the OOD detection signal you want before the robot does something catastrophically wrong.
Activation Mahalanobis distance — collecting the training distribution \(\{h_l^{(i)}\}\) at layer \(l\) and fitting \(\mathcal{N}(\mu_l, \Sigma_l)\), the Mahalanobis distance at inference:
$$d_M(h_l) = \sqrt{(h_l - \mu_l)^\top \Sigma_l^{-1} (h_l - \mu_l)}$$gives you a principled model-internal OOD detector that requires no separate classifier. \(\Sigma_l^{-1}\) is computed offline once; at inference you just do a matrix-vector multiply with negligible cost relative to the attention computation you're already paying for.
Mixed-precision quantization is architecture-sensitive, not uniform. Jetson Thor delivers exactly 2x the TFLOPS at FP4 vs FP8, which makes the temptation to run everything in FP4 obvious — but it's wrong in a predictable way if you understand which layers are doing what. Early ViT layers doing low-level visual processing are robust to FP4. Mid-to-late language model layers doing semantic processing are moderately sensitive. The cross-attention layers where "pick up the mug" gets grounded to the specific visual features of the specific mug in the camera frame are highly sensitive — quantizing these to FP4 destroys fine-grained spatial grounding in ways that don't show up on aggregate benchmarks but manifest clearly on precise localization tasks. The right schedule assigns FP16 to visual cross-attention, FP8 to language model self-attention, and FP4 to MLP feed-forward layers, recovering most of Thor's FP4 speedup while preserving precision where it matters. Nobody has done the calibration study on a production VLA to find the exact quality cliff. This is tractable, important, and unfinished.
Where this goes
Robotics is in the middle of a capability revolution that's real. Physical Intelligence can run a model that folds laundry in your house, cleans up a kitchen it's never seen, and improves from its own deployment experience through RECAP. Yunzhu Li's RoboPIL can generalize to novel objects zero-shot through structured 3D descriptors, generate relational constraints from VLMs without any task-specific training data, and compress dynamics learning and visual prompting into a single sparse keypoint representation. The science isn't vaporware and the results are genuinely impressive.
But there's a version of the near future that's unambiguously better than the one we're currently building toward, and we're not building toward it fast enough. In the version we're building, each robot company trains a large VLA, finetunes it on their specific hardware and task distribution, ships a TensorRT-compiled binary for their specific Jetson SKU, monitors deployments with ROS2 bag files and occasional SSH sessions, and debugs failures by flying a roboticist to the site to watch the robot fail repeatedly until pattern-matching reveals a fix. The iteration cycle is months, observability is zero, and the infrastructure is hand-rolled from scratch at every company. This is the GPT-3 API era for robotics, and it will work badly in the same ways the GPT-3 API era worked badly.
In the better version, there's a VLA inference serving runtime that understands chunk structure and implements RTC-style scheduling as a primitive, manages multi-model memory with PagedAttention-style KV paging across semantic and motor models, maintains a temporal visual feature cache and reuses KV blocks across control steps and denoising iterations, exposes attention entropy, activation Mahalanobis distance, and denoising curvature as a real-time observability sidecar, and applies structure-aware mixed-precision quantization calibrated to each VLA's sensitivity profile — all running on Jetson Thor at 50Hz within the 130W power envelope. The robot companies plug their VLA into this runtime the way web companies plug their application into nginx, the infrastructure is shared, and the iteration cycle drops from months to days.
The LLM community built this ecosystem over three years of painful engineering — vLLM (2023), FlashAttention-3 (2024), ThunderKittens and megakernels (2024-2025), SGLang, TensorRT-LLM — because the people who built it were frustrated enough by the waste (50% of H100 bandwidth sitting idle, memory fragmentation inflating serving costs by 10x) to fix it. Robotics doesn't have this yet, but the frustration is building — you can see it in the proliferation of ad-hoc chunking solutions (RTC, A2C2, PD-VLA), in the measurement studies trying to characterize the onboard-vs-offload tradeoff, in the sim2real gap papers that keep finding 12-18% degradation without a clear path to fixing it. The field knows something is wrong, it just doesn't yet have the vocabulary to describe what the right infrastructure looks like, because the people who could build it are mostly not yet in the robotics community.
The gap isn't in generalization — the models generalize. It isn't in hardware — Jetson Thor is genuinely good enough. It's a gap in systems thinking applied to a new class of problem with a fundamentally different structure than the LLM serving problem that produced the current toolkit. The teams that close it first will compress the robotics deployment iteration cycle from months to days, and that's not a marginal improvement in pace but a qualitative change in what becomes possible.
We're working on this. If you're thinking about VLA inference systems, structured world model representations, or hardware-software co-design for edge robotics, we'd like to talk.
Further Reading
VLA Architecture and Deployment
- π₀: A Vision-Language-Action Flow Model for General Robot Control — Black et al. (Physical Intelligence), 2024
- π₀.5: A VLA with Open-World Generalization — Physical Intelligence, arXiv 2504.16054, 2025
- π₀.6 (RECAP): A VLA That Learns From Experience — Physical Intelligence, arXiv 2511.14759, 2025
- Real-Time Execution of Action Chunking Flow Policies (RTC) — Black et al., arXiv 2506.07339, 2025
- Leave No Observation Behind: Real-Time Correction for VLA Action Chunks (A2C2) — arXiv 2509.23224, 2025
- PD-VLA: Parallel Decoding for VLA Acceleration — arXiv 2503.02310, 2025
Structured World Models and Representations
- D3Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement — Wang, Zhang, Li et al., CoRL 2024
- ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints — Huang, Wang, Li et al., RSS 2024
- KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting — RoboPIL (Yunzhu Li lab), 2025
- Diffusion Policy — Chi et al., RSS 2023
Inference Systems
- vLLM / PagedAttention — Kwon et al., SOSP 2023
- ThunderKittens: Simple, Fast, and Adorable AI Kernels — Spector et al. (Hazy Research), 2024; v2.0 with Blackwell support, 2026
- Look Ma, No Bubbles! Designing a Low-Latency Megakernel for Llama-1B — Spector et al. (Hazy Research), 2025
- ThunderMLA: FlashMLA, Faster and Fused-er — Spector et al. (Hazy Research), 2025
Edge Deployment and Measurement
- Offload or Overload: A Platform Measurement Study of Mobile Robotic Manipulation Workloads — Pohland et al., arXiv 2603.18284, 2026
- NVIDIA Jetson Thor: The Ultimate Platform for Physical AI — NVIDIA Technical Blog, January 2026
- Crossing the Sim-to-Real Gap: Training Spot Quadruped Locomotion with NVIDIA Isaac Lab — NVIDIA / Boston Dynamics, 2025